TL;DR
- I fine-tuned Llama 3.2 3B to clean and analyze raw voice transcripts fully locally, outputting a structured JSON payload (title, tags, entities, dates, actions, etc.).
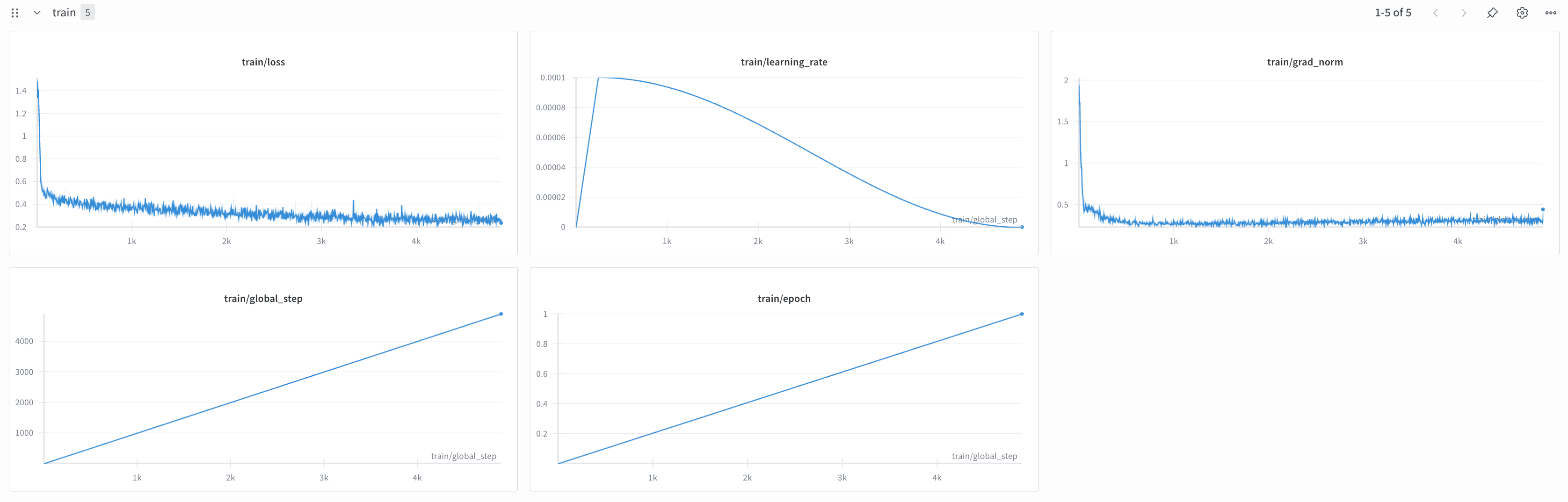
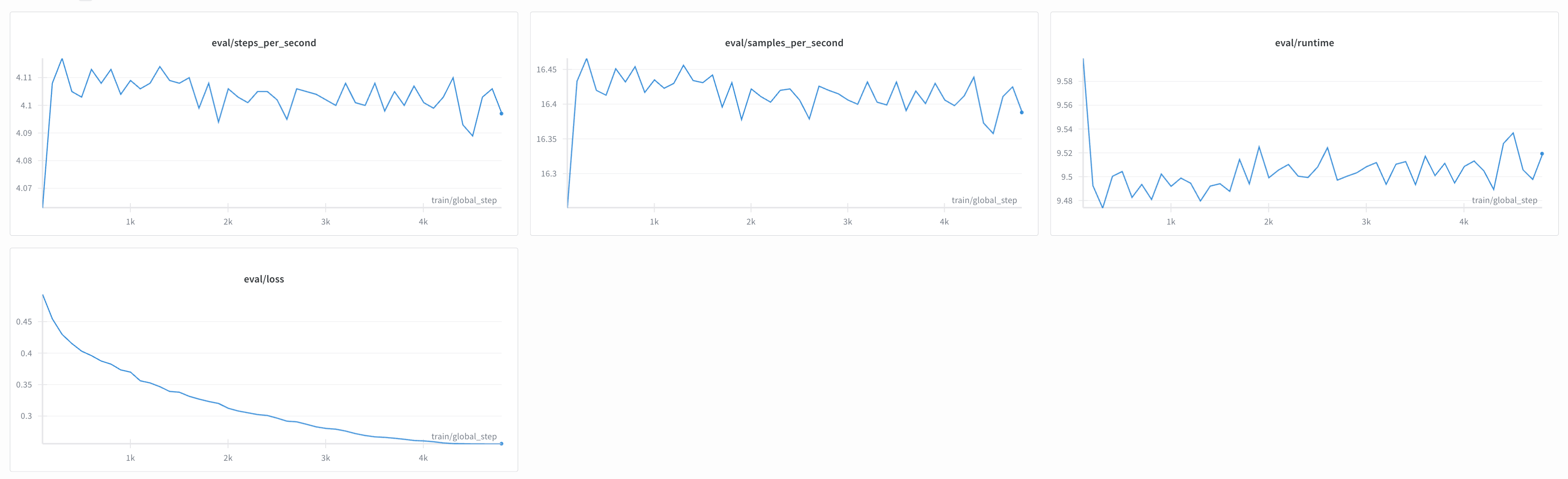
- Training: LoRA via Unsloth taking 4 hours on a single 4090, (batch size 16).
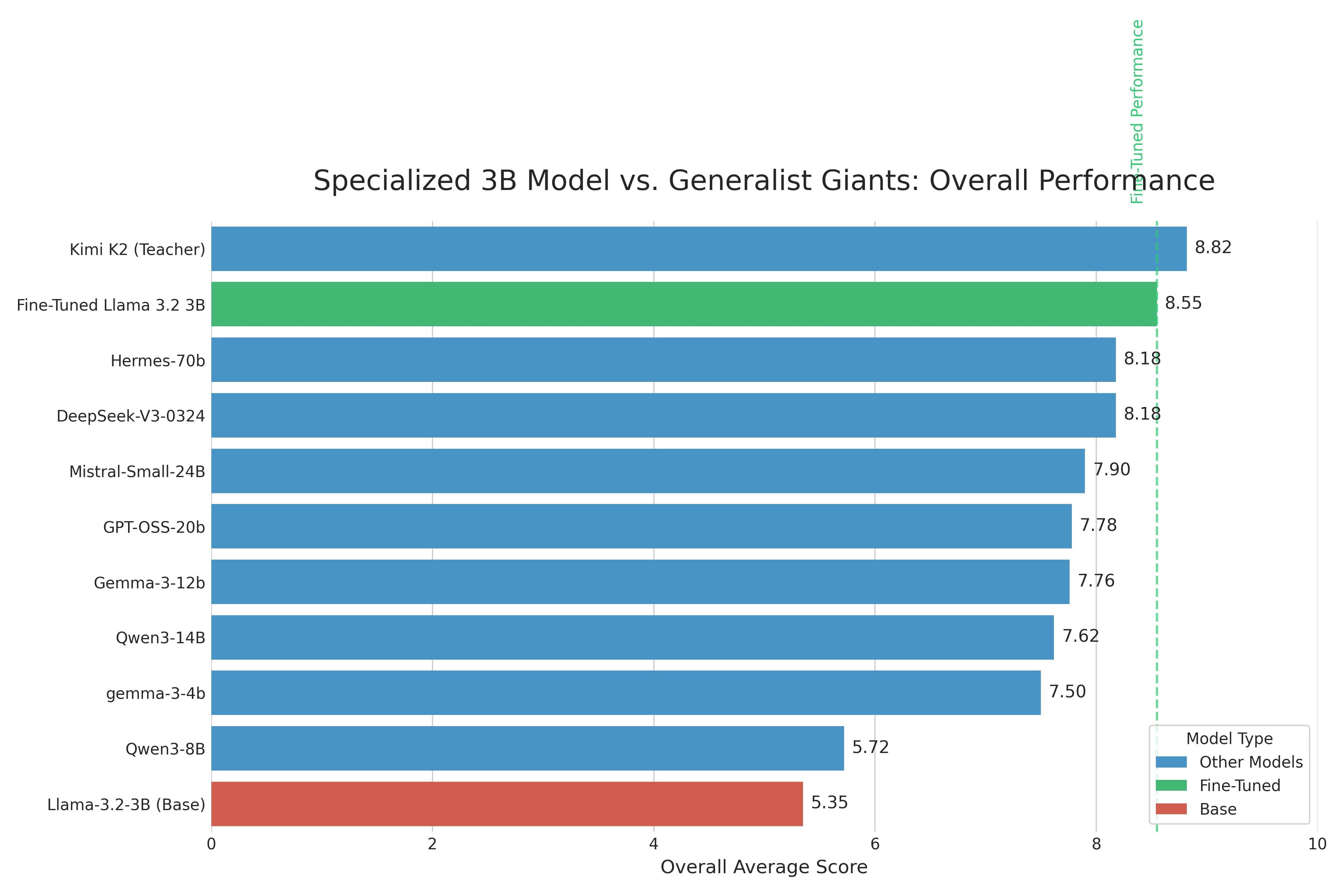
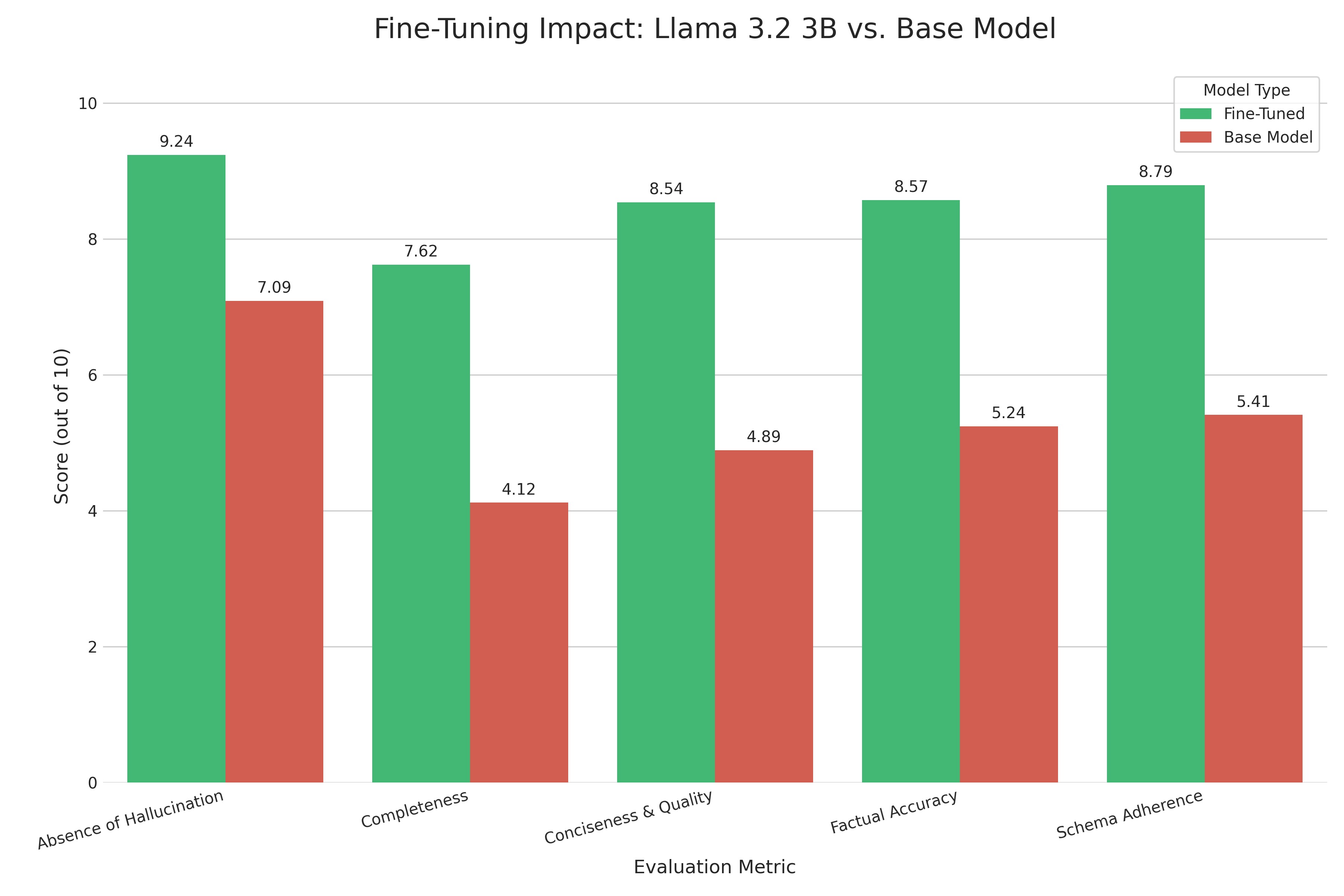
- Results: Overall eval score jumped from 5.35 (base) → 8.55 (fine-tuned). Beats many larger 12B–70B general models on this task.
- Inference: Merged → GGUF (Q4_K_M) for local use; works great in LM Studio.
- Download the 4-bit model below and see example HTML card outputs.
Backstory
I have a simple app (lazy-notes) that watches a folder for new audio files and transcribes them using either Whisper or Parakeet. My old workflow involved sending these transcripts to OpenRouter for cleanup and analysis. This worked, but it felt a bit disconnected. Since the transcription was already happening locally, I wondered if I could handle the cleanup and analysis locally too.
I gave it a shot with the base Llama-3.2-3B model and a detailed prompt. The results were okay, but not great. It often missed entities, struggled with dates, and the output was generally incomplete. This seemed like a perfect use case for supervised fine-tuning (SFT).
Dataset
To get started, I took 13 random voice memos from my app and used their raw transcripts as a seed. My data generation process was handled by a Python script I wrote (pipeline_transcripts_core.py) that automates the whole pipeline.
First, the script takes my real transcripts and sends them to a state-of-the-art "teacher" model (in this case, Kimi K2) to generate a "gold standard" JSON output for each one. This is the exact structure and quality I want my final model to produce. I manually checked these and was happy with the output.
Next, I used those real examples to prompt the teacher model to generate over 40,000 synthetic raw transcripts using this script. The idea was to create a massive dataset of messy, realistic dictations. Each of these new synthetic transcripts was then also sent to the teacher model to get a corresponding gold-standard JSON output. Finally, the script bundled everything into a single JSONL file, ready for training.
Get all dataset & training related code and scripts here.
Training
I trained the model on an RTX 4090, which took about 4 hours with a batch size of 16. For this, I used another script (train.py) built around the Unsloth library to make training as fast as possible. Shoutout to the team at Octa who generously provided the credits for this!
This script handles loading the dataset and formatting each user-assistant pair into the Llama 3 chat template. A key step here is JSON canonicalization: the script sorts all the keys in the JSON output into a consistent, predefined order before training. This matters because the model won't get confused or penalized for producing the right data in a different order. Once the data is prepped, the script kicks off the SFT process using LoRA and saves the final model adapters.
Hyperparameters
Here are the hyperparameters I used for training:
| Hyperparameter | Value |
|---|---|
lora_r |
128 |
lora_alpha |
128 |
lora_dropout |
0.05 |
batch_size |
16 |
grad_accum |
1 |
epochs |
1 |
lr |
5e-5 |
warmup_ratio |
0.05 |
weight_decay |
0.1 |
scheduler |
"cosine" |
max_grad_norm |
1.0 |
seed |
3407420 |
logging_steps |
1 |
eval_steps |
200 |
save_steps |
200 |
save_total_limit |
6 |
project |
"transcripts-llama3-sft" |
run_name |
None |
Inference
To make inference simpler, I merged the trained LoRA with the HF model to produce a GGUF. I then quantised this to 4-bit Q4_K_M and used LM Studio to talk to it.
This is how I create the JSON object:
\n\nRight, Monday the fifteenth of January twenty twenty four okay, Dr Patel 10 am stroke building second floor, take the uh, the, the blood forms from last week, oh and remember dentist Friday uh no wait that's the twenty sixth no twenty third, bugger where's the NHS app. Also pick up Mia after school, her mum's got a uh whatever they call it at the council, interview I think. Bread, lactose free milk, and those uh sour strawberry laces she likes. Might as well book MOT online while I'm waiting, March isn't it? Or was it April. Shit, mental note check logbook. Alexa play the Arctic Monkeys playlist actually no I'm sick of them already.\n
Inference parameters:
- Temperature: 0.1
- Limit Response Length: Off
- Top K Sampling: 40
- Repeat Penalty: 1.1
- Min P Sampling: 0.05
- Top P Sampling: 0.95
{"title":"Monday 15 Jan 2024 Errands","cleaned_transcript":"Right, Monday the fifteenth of January twenty twenty four okay, Dr Patel 10 am stroke building second floor, take the blood forms from last week, oh and remember dentist Friday uh no wait that's the twenty sixth no twenty third, bugger where's the NHS app. Also pick up Mia after school, her mum's got a whatever they call it at the council, interview I think. Bread, lactose free milk, and those sour strawberry laces she likes. Might as well book MOT online while I'm waiting, March isn't it? Or was it April. Shit, mental note check logbook. Alexa play the Arctic Monkeys playlist actually no I'm sick of them already.","category":"Planning","tags":["appointments","errands","family","mot"],"summary_short":"Monday 15 Jan 2024: Dr Patel stroke appointment at 10am, dentist on 23rd, pick up Mia after school, buy groceries and book MOT.","key_points":["Dr Patel appointment Monday 15 Jan 2024 at 10am","Dentist appointment Friday 23rd January","Pick up Mia after school from mum's interview","Buy bread, lactose free milk, sour strawberry laces","Book MOT online (check logbook)"],"action_items":[{"description":"Take blood forms to Dr Patel appointment","due":"Monday 15 Jan 2024","priority":"H"},{"description":"Find NHS app for dentist booking","due":"","priority":"M"},{"description":"Pick up Mia after school","due":"Friday 23rd January","priority":"H"},{"description":"Buy groceries: bread, lactose free milk, sour strawberry laces","due":"","priority":"L"},{"description":"Book MOT online and check logbook","due":"","priority":"M"}],"decisions":[],"questions":["Was MOT booking March or April?"],"people":["Dr Patel","Mia"],"entities":[{"text":"NHS app","type":"ORG"},{"text":"Arctic Monkeys playlist","type":"PRODUCT"}],"time_extractions":{"kind":"DATE","normalized":"2024-01-15","text":"Monday the fifteenth of January twenty twenty four"},{"kind":"TIME","normalized":"10:00","text":"10 am"},{"kind":"DATE","normalized":"","tex...
Evals
The first evaluation was a sanity check: fine-tuned model vs. base model. I took 100 random samples from my validation set and compared my model's output against the base Llama 3.2 3B and the gold-standard reference (created by Kimi K2 in the previous step). For the eval model, I chose [GLM 4.5 FP8 (355B) because I wanted a powerful model that was not involved in building the initial dataset.
Results
The fine-tuning made a huge difference. My model's overall score jumped from a mediocre 5.35 to a solid 8.55. The biggest gains were exactly where I needed them: Completeness went from 4.12 to 7.62, and Factual Accuracy climbed from 5.24 to 8.57. It learned to stop making stuff up and find all the details I cared about.
But the more interesting question was: how does this little 3B model stack up against bigger, off-the-shelf models?
Comparing it against the giants
To see if this project was really worth it, I put my fine-tuned model up against a gauntlet of larger, non-fine-tuned models. This is the classic specialization-vs-scale test. I used a smaller 10-sample set for this and ran them through models ranging from 4B all the way to 70B.
Here's how they ranked based on their overall average score on this task.
| Rank | Model | Size | Overall Score |
|---|---|---|---|
| 1 | Kimi K2 (Teacher Model) | ~1T (32B active) | 8.82 |
| 2 | My Fine-Tuned Llama-3.2-3B | 3B | ~8.40* |
| 3 | Hermes-70B | 70B | 8.18 |
| 4 | DeepSeek-V3-0324 | 671B (37B active) | 8.18 |
| 5 | Mistral-Small-24B | 24B | 7.90 |
| 6 | GPT-OSS-20b | 20B | 7.78 |
| 7 | Gemma-3-12b | 12B | 7.76 |
| 8 | Qwen3-14B | 14B | 7.62 |
| 9 | Gemma-3-4B | 4B | 7.50 |
| 10 | Qwen3-8B | 8B | 5.72 |
| 11 | Llama-3.2-3B (Base Model) | 3B | 5.35 |
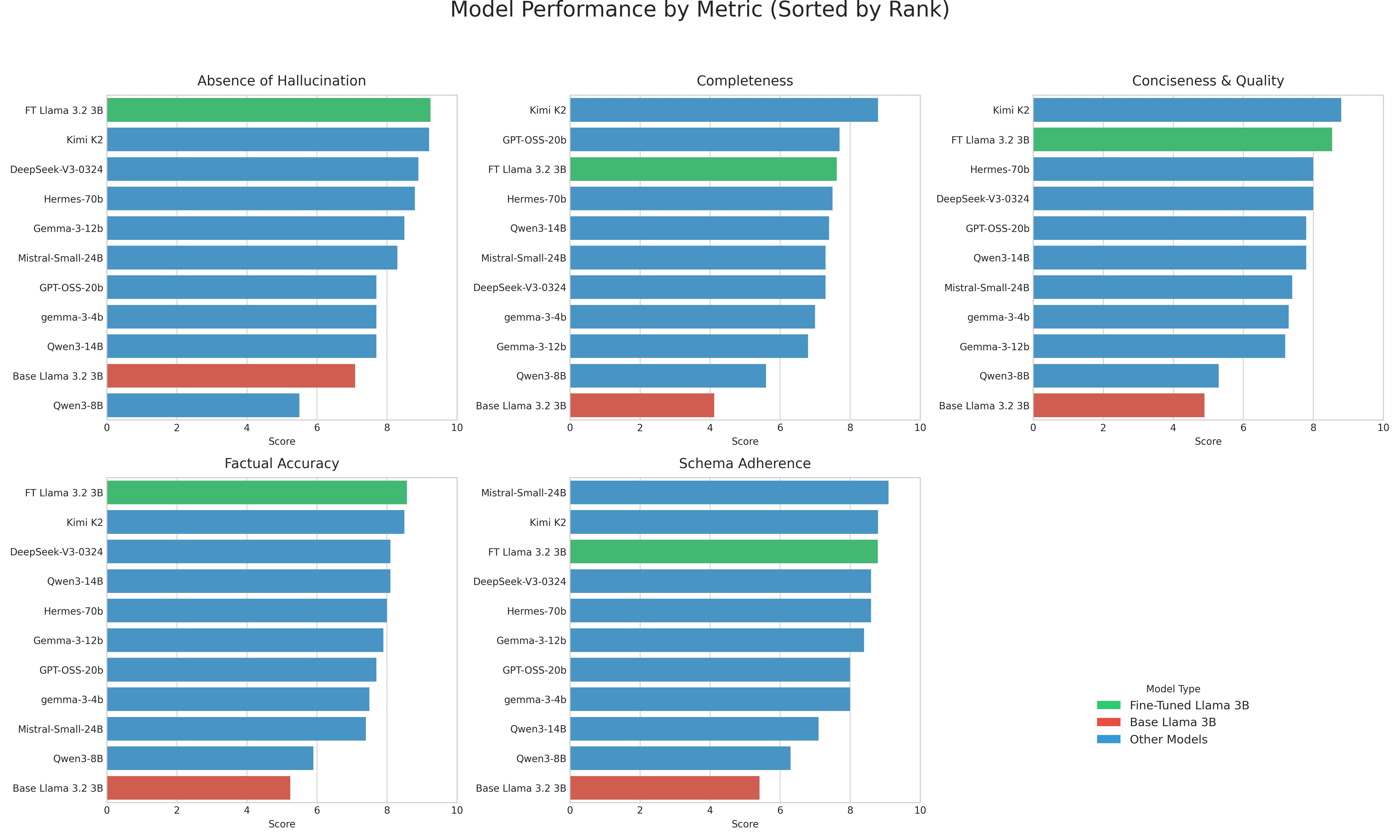
The results were pretty wild. My little 3B model beat almost everything I threw at it, including models that are 5–8x its size. I expected the bigger models to be much better.
Of course, it didn't beat Kimi K2, which makes sense since that was the teacher model it learned from. The 70B Hermes model also performed very well. But the fact that my specialized model is in the same league, and is clearly outperforming most other general-purpose models, is exactly what I was hoping to see.
Conclusion
So, was it worth it? For me, 100%. I spent a few days setting up the scripts, generating the datasets (thanks to Chutes' 5000 reqs/day limit with their $20/m plan), and now I have a tool that's perfectly tailored to my workflow. It's fast, it runs entirely on my own machine, and it gets the job done better than most general models I could use via an API.
This whole process really drove home for me that we don't always need a bigger model, we just need the right model. A small, focused model can be incredibly powerful when you train it on the exact task you need it to do. If you have a repetitive text-based task, it's definitely worth looking into what a small-scale fine-tune can do for you. Perhaps I could help you in doing so?
Download 4-bit GGUF